# - Dataset Augmentation in Feature Space. (ICLR-17 workshop)

interpolation和extrapolation
# - A Closer Look At Feature Space Data Augmentation For Few-Shot Intent Classification. (EMNLP-19 workshop)
利用两个样本的difference来应用到第三个样本上,从而产生新样本。
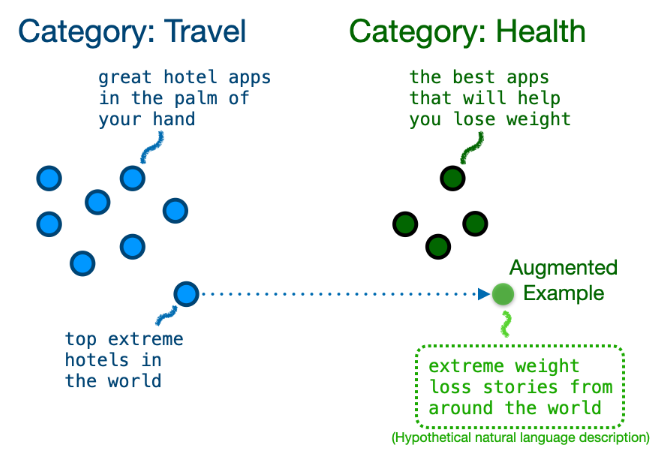
# - Good-Enough Example Extrapolation. (EMNLP-21)
设计了一种跨类别的增强方法:
# - Feature Space Augmentation for Long-Tailed Data. (ECCV-20)
提出使用资源丰富的类别来指导低资源/长尾类别的数据增强,从而复原低资源类别所缺失的信息。
设计了一个class activation map,来对feature的每个维度进行区分,得到class-specific feature和class-generic feature:

最终的目的是为了把那些大类的generic feature取出来,跟小类的specific feature混合从而丰富小类的特征。
整体流程图:

这背后的思想是有意义的:一个样本的各个位置(图片pixel或者文本的token)对于它所属的类别的影响力是不一样的,比如object detection中的物体的背景就不太重要,甚至把这个背景放到其他类别中,也是没问题的。所以本文就是想在特征空间上,把大类的不重要特征,迁移到小类上,从而辅助小类形成一个更丰富的分布。
这种思想是很好的,但是我感觉在特征空间上这么做,可能没有直接在raw input空间上做好,因为原始特征经过神经网络复杂的变换已经进行了深度的融合,这时,即使相对那么不相关的特征,也可能跟类别是有很强的相关性的,不一定能很好地迁移到其他类别。而原始输入空间,则不会有太大这种问题,而关键在于如何找出真正跟类别有关、无关的位置。所以各有难处。
我上面的猜想,在论文中也得到了了部分验证。作者提到:"we observe that the “nearby” classes in the feature space, i.e. the most “confusing” classes with respect to the given tail class, have the biggest impact on recovering the previously ill-defined decision boundary.",即只有当两个类别本身就比较接近时,才能较好得进行迁移特征。
下图展示了两阶段的训练和验证准确率:

- take away:这个文章主要解决label imbalance问题,而有一些loss设计就是专门处理这个问题的,比如 Class-balanced Loss (CB loss)和著名的Focal Loss。这两个都可以去了解一下。