# Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification
- 会议期刊:EMNLP 2021
- 机构:Peking University, WeChat AI
- 代码:https://github.com/lancopku/text-autoaugment
# 核心思想
提出了一种组合式、可学习的数据增强范式,探究“如何组合、调优各种不同的数据增强方法,以取得更好的增强样本”的问题。简单来说就是我们有了各种增强方法,如何构建一个最优的“投资组合”,来让最终的增强样本带来的收益最大。
而由于如何组合、什么顺序、什么程度这些都是超参数,无法用传统的基于梯度的方法来优化,因此本文使用了AutoML中常用的贝叶斯优化来进行这些超参数的调节。
# 跟传统方法的对比

传统方法,要么超参数是靠经验来设置(比如EDA、BT),要么可以学,但是是单一的增强方法(比如LDM,使用强化学习来调参)。而本文的TAA则是可学习的、组合式的增强。
# 流程图
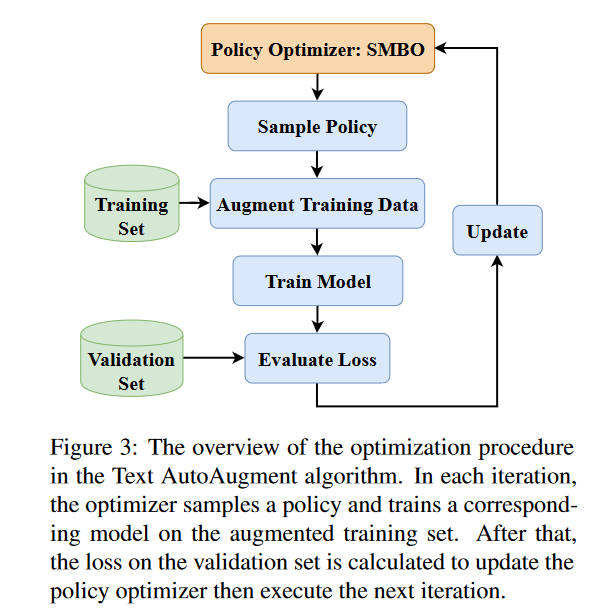
其实看下来,你说真正多大的创新吧,也没有,上图中,把使用AutoML的SMBO算法来调参给换成grid search、random search之类的传统调参方式,那就跟传统的增强没有太大区别:先跑一组超参看看,根据验证集的效果,再调整超参数。只不过之前我们调参的时候,没有太多理论的指导,而这里则是基于贝叶斯优化等理论来进行调参,所以最终寻找到的参数组合当然更好。
所以,总体看,这篇文章是“现有算法”迁移到“新任务”上,取得了不错的效果,虽然理论上的创新不大,不过整个论文的叙述、实验都比较solid,所以是一个不错的工作。
# 实验设计
本文我觉得主要优点在于实验非常丰富。这一点是值得学习的。本文设计的实验如下:
# 主实验:
- 低资源场景:数据集都只使用少量的训练样本;
- 类别不平衡场景;
- 高资源场景(作者成为“可扩展性”):当训练集充足时的实验,这里作者直接使用在低资源场景下调参的结果来跑。
补充实验(参数分析):
- 参数策略迁移实验:将一个数据集的超参数方案,直接迁移到另一个数据集上,看看稳定性;
- 增强样本数量的实验;
- 参数策略的结构;
- 增强样本的多样性对比:使用“Dist-2”的指标,来衡量数据集的多样性;
- 语义相似度(增强样本的语义保留情况)的对比:使用Sentence-Bert来计算样本间相似度;
所以,这么多的实验,哪怕核心理论贡献并不大,但是大家可以从实验中了解到很多新知识,或者验证很多我们的猜想,这是我认为这个工作的价值所在。
# Take Away
- 超参数也是可以学习的,这正是AutoML领域研究的重点。在网上看到一个写的不错的博客:https://towardsdatascience.com/a-conceptual-explanation-of-bayesian-model-based-hyperparameter-optimization-for-machine-learning-b8172278050f
- 衡量一个语料的多样性(diversity),可以使用distinct-1、distinct-2等指标。这个指标最初在论文 A Diversity-Promoting Objective Function for Neural Conversation Models 中提出。