# 郭必扬 Biyang Guo

- E-Mail: guo_biyang(@)163(dot)com
- 中文简历 (opens new window) | English CV (opens new window)
- Github (opens new window) | Google Scholar (opens new window) | 知乎 (opens new window) | SimpleAI公众号 (opens new window)
我目前是上海财经大学信息管理与工程学院 (opens new window) AI Lab 三年级博士生(2020~2024),师从黄海量 (opens new window)教授,韩松桥 (opens new window)副教授。硕士、本科均就读于上海财经大学信管学院。博士期间主要研究NLP中的数据增强、以数据为中心的 AI、更鲁棒的文本分类等。相关成果发表于 AAAI 会议,并有多篇工作在审稿中。
曾在微软亚洲研究院(MSRA) (opens new window) NLC 组进行 9 个月(2022.3~2022.11)的研究实习,由宫叶云 (opens new window)博士、段楠 (opens new window)博士指导。实习期间提出 GENIUS 模型 (opens new window),一个强大的基于草稿的文本生成预训练模型,可用于多种NLP任务的数据增强。
作为 SimpleAI 社区 (opens new window)的创始人,在 ChatGPT 推出仅 10 天,组建了一个博士生、工程师团队,开展 ChatGPT 对比与检测 (opens new window)项目,推出首个开源的人类-ChatGPT问答对比语料集(HC3) (opens new window)和首个中英双语 ChatGPT 内容检测器 (opens new window),推出一个月累计访问量超过 2 万次、GitHub Stars 超过 , 开源模型和数据集月均下载数千次。
# 学术研究/项目
# ➤ ChatGPT 对比与检测 (preprint)
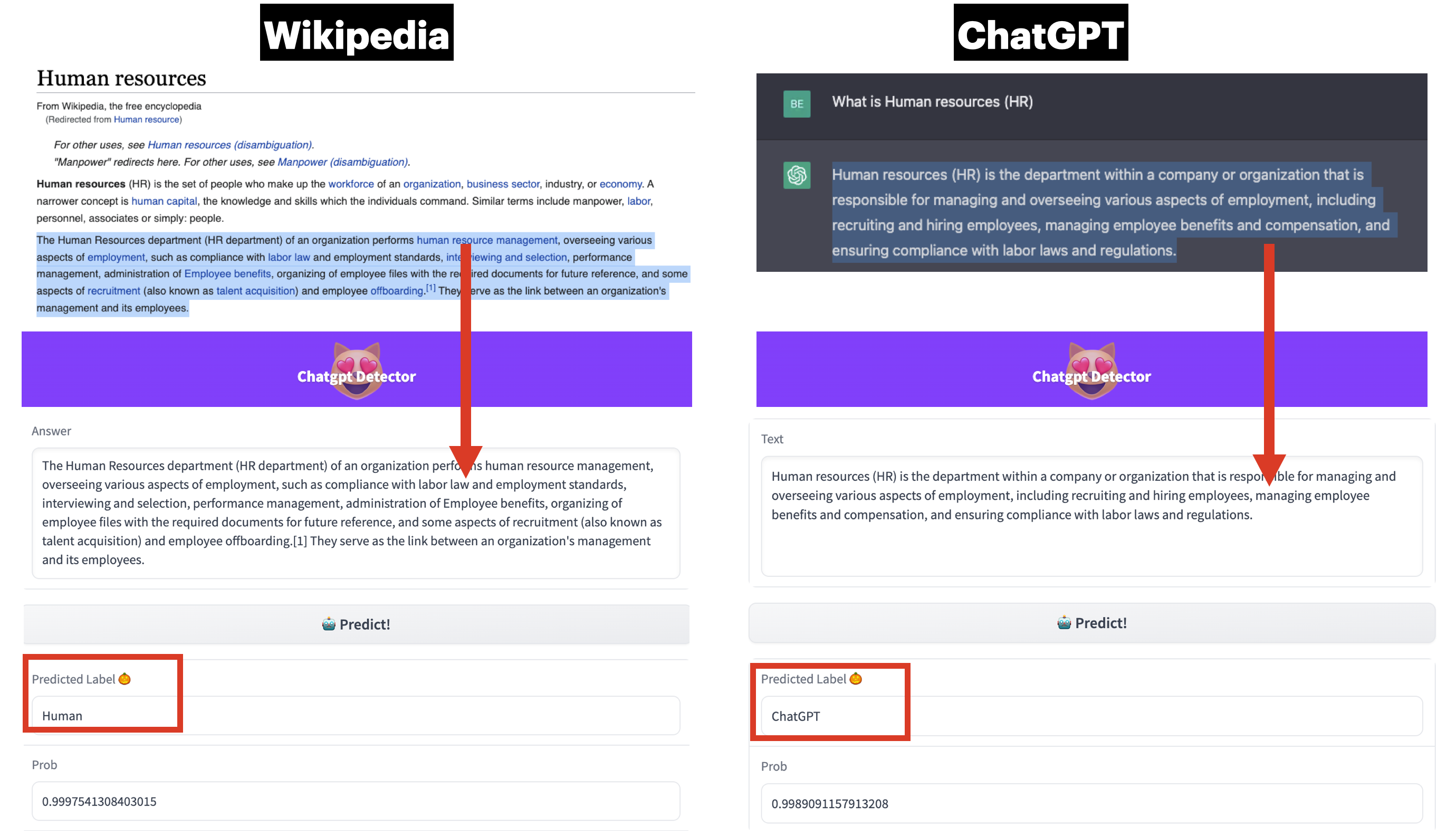
- 论文: How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection (opens new window) (Biyang Guo, Xin Zhang, Ziyuan Wang, Minqi Jiang, Jinran Nie, Yuxuan Ding, Jianwei Yue, Yupeng Wu)
- Github page (opens new window)
- 角色:项目发起人、负责人 | SimpleAI 社区,SUFE AI Lab
- 简介:ChatGPT的推出引起了学术界、业界的巨大轰动,ChatGPT生成的内容开始充斥各大UGC平台,并开始被用于作假、作弊,对互联网、教育等等行业产生了巨大威胁。基于此,我发起 ChatGPT 对比与检测项目,组建由8位国内外高校、企业的博士生、工程师,共同收集人类-ChatGPT对比数据,进行丰富的统计、语言学等分析,并基于深度学习、机器学习等技术,开发了一系列ChatGPT 内容检测器。据我们了解,我们是学术、产业界最早开源对比数据集、检测器模型的团队,目前检测器demo全球访问量已突破2万,用户覆盖5大洲,开源模型月均下载量超过3K,数据集月均下载量超过1K,Github Stars 超过 512,受到广大用户的认可和产业界的关注。相关学术论文预印版已发布于Arxiv平台,一个月内被国际同行引用 7 次。
- 访问在线 Demo:ChatGPT detectors 🔥 (opens new window)

# ➤ GENIUS – 基于草稿的文本生成模型 (preprint)
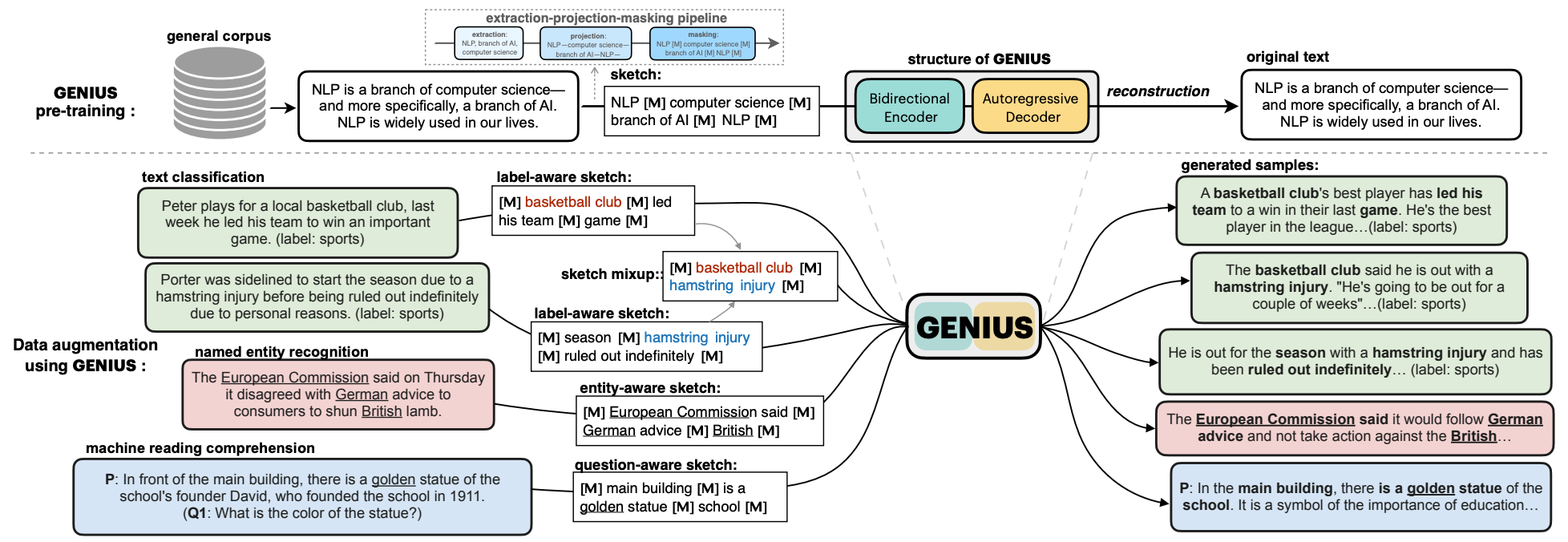
- 论文:GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation (opens new window) (Biyang Guo, Yeyun Gong, Yelong Shen, Songqiao Han, Hailiang Huang, Nan Duan, Weizhu Chen)
- Github page (opens new window)
- 角色:第一作者 | SUFE AI Lab,MSRA
- 简介:GENIUS 我在MSRA访问实习期间做的工作。是一个基于草稿的生成式语言模型(sketch-based generative language model),在超过2700万语料上进行大规模预训练,从而可以基于少量的关键词、短语等信息生成内容丰富的文本段落。GENIUS可用于写作辅助、残缺信息填补,更是一个开箱即用的通用的 NLP 数据增强工具,我们在分类、实体抽取、机器阅读等任务上验证了GENIUS作为数据增强工具的有效性。相关模型开源在Huggingface平台,模型月均下载量超过 500 次。
- 访问在线 Demo:GENIUS 💡 (opens new window)

# ➤ STA – 针对性文本增强技术 (preprint)

- 论文:Selective Text Augmentation with Word Roles for Low-Resource Text Classification (opens new window) (Biyang Guo, Songqiao Han, Hailiang Huang)
- Github Page (opens new window)
- 角色:第一作者 | SUFE AI Lab
- 简介:STA 是对传统NLP数据增强技术的一个改进,使用语义相似度和统计相关度对一个词的角色进行区分,然后针对性地进行数据增强。使用了STA方法的改进,传统的基于规则的方法可以媲美甚至超越基于大型语言模型(BERT、BART、GPT-2)的方法,且计算成本显著更低。

# ➤ LCM – 标签混淆学习,更鲁棒的文本分类 (AAAI-21)
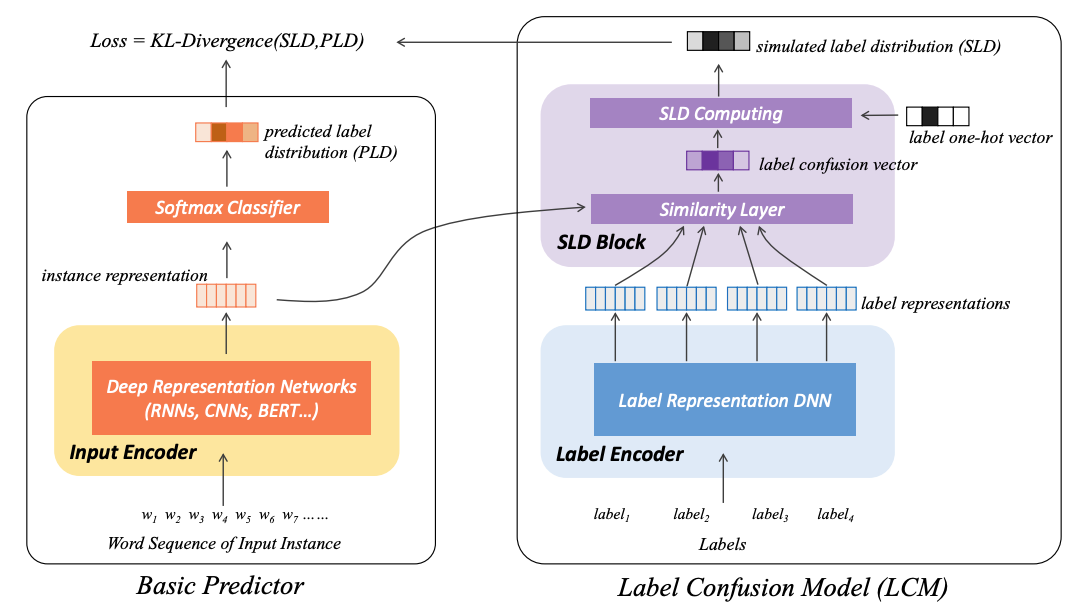
- 论文:Label Confusion Learning to Enhance Text Classification Models (opens new window) (Biyang Guo, Songqiao Han, Xiao Han, Hailiang Huang, Ting Lu)
- Github page (opens new window)
- 角色:第一作者 | SUFE AI Lab
- 简介:我们提出在经典深度学习分类器的基础上添加一个LCM 插件,LCM 可以在模型训练的过程中学习不同标签之间的重叠、相似关系,从而模拟一个比 one-hot 分布更加合理的标签分布,使用这个改进后的标签分布来指导模型训练可以使模型在数据有噪音、标签易混淆的场景下获得显著性能提升。

# 社区动态
✦ 科普作者. 我是⼀名技术科普爱好者,喜欢并追求将艰深复杂的理论知识⽤通俗易懂的语⾔描绘出来。在科研之外的时间,我喜欢撰写技术博客,进⾏模型、论⽂解读。代表作品如下:
- OpenAI是如何“魔⻤调教” GPT的?InstructGPT论⽂解读 (opens new window), 2022 (知乎 160+ 赞)
- 通俗科普⽂:⻉叶斯优化与SMBO、⾼斯过程回归、TPE (opens new window), 2022 (知乎 220+ 赞)
- 理解L1, L2正则化的正确姿势 (opens new window), 2021 (知乎 260+ 赞)
- 整理了12⼩时,只为让你20分钟搞懂Seq2Seq (opens new window), 2021 (知乎 900+ 赞)
- 何时能懂你的⼼——图卷积神经⽹络 (GCN) (opens new window), 2019 (知乎 3500+ 赞)
- 从此明⽩了卷积神经⽹络 (CNN) (opens new window), 2018 (知乎 2600+ 赞)
包含上述作品在内,我在「知乎」上收获近 2 万粉丝,专栏⽂章被点赞超 2 万次,收藏超 3.5 万 次,多篇⽂章被收录为知乎圆桌精选,获得众多深度学习和⾃然语⾔处理领域同学的认可。
✦ 我的组织. 在技术科普的基础上,本⼈创办并运营 「SimpleAI 」公众号和社区,受众超过 1万 ⼈。2022年底在 ChatGPT 推出之后,在 SimpleAI 社区内召集来⾃国内外 6 所⾼校、企业的博⼠ ⽣、⼯程师,开发并开源世界⾸款 中英双语 ChatGPT 内容检测器和相关数据集,在国内外取得较⼤反响,相关成果⻅上文项目部分。 这也是让我⼗分难忘的社区科研和团队管理经历。
✦ 开源项⽬. 我在 GitHub 上创建了多个开源项⽬,累计收获近 900 Stars。我以及我创办的组织在 Hugging Face 平台上开源了 8 个深度学习模型和 3 个数据集,每⽉被社区下载数千次。我同时加⼊了 Hugging Face 中⽂翻译创始组,为中⽂社区翻译相关技术课程。
✦ 学术审稿⼈. 在学术社区,担任 ACL, EMNLP, Applied Intelligence, Information & Management 等会议或期刊的志愿审稿⼈。